Wilfried Rohm, HTBL Saalfelden
| Statistik mit Zufallszahlen |
Mathematische Inhalte:
Beschreibende Statistik : Mittelwert, Häufigkeiten.
Wahrscheinlichkeitsrechnung : Berechnen von Wahrscheinlichkeiten mittels
Kombinatorik , Erwartungswert, Binomialverteilung.
Höhere Statistik: Testtheorie (c 2-Test).
Anwendung:
Test von Reihen von Pseudozufallszahlen auf "Zufälligkeit",
Überprüfung der Zufallszahlen-generatoren vorliegender Geräte
(Taschenrechner,PC,...), allgemeine Anwendungen des Chiquadrattestes beim
Vergleich von theoretischen und beobachteten Verteilungen.
Kurzzusammenfassung:
Der Artikel besteht aus 4 Teilen:
- Ein Experiment (Der Run-Test) bietet einen interessanten Einstieg
in die Denkweise der Statistik. (parallel dazu Verwendung des Programmteiles
"Runtest" )
- Es werden Beispiele für Algorithmen angeführt, nach denen
Pseudozufallszahlen erzeugt werden können.
- Der Poker-Test (Programmteil "Pokertest") zeigt graphisch
und rechnerisch, wie Pseudo-zufallsgeneratoren im Vergleich zu "wirklichen"
Zufallszahlen abschneiden.
- Im ANHANG werden neben Hinweisen zum Programmablauf einige markante
Bilder (Situationen) aus den beiden Programmteilen als Bildschirm-Hardcopys
wiedergegeben.
Lehrplanbezug:
Beschreibende Statistik, Wahrscheinlichkeitsrechnung , Prüfverteilungen.
(je nach Abteilung
in verschiedenen Jahrgängen vorgesehen)
Mediales Umfeld:
Verwendete Medien: IBM-kompatibler
PC mit VGA-Grafik 640x480 Punkte.
Verwendete Software : Turbo-Pascal 6.0
Dateien zum Herunterladen:
RO-STATC.EXE:
Ablauffähiges Programm mit Verwendung von Farben ("C"olors)
RO-STATM.EXE:Ablauffähiges
Programm, das auf die Verwendung eines "M"onochrom- Bildschirmes
(z.B. Overheaddisplay) zugeschnitten ist .
HINWEIS: Der ebenfalls auf zum Herunterladen befindliche Grafiktreiber
(EGAVGA.BGI) und die
Schriftdateien (*.CHR) sollten
im selben Directory wie das Programm stehen.
Anmerkungen:
Das Programm und die damit zusammenhängenden theoretischen Fragestellungen
können und sollen auf verschiedenem Niveau (Jahrgängen) behandelt
werden. Es wird einerseits (insbesondere mit dem Runtest) eine Einführung
in die Begriffswelt und das Denken der Statistik geboten.
Andererseits bietet der Pokertest einen reizvollen Einstieg in höhere
Sphären der Statistik (Zufallsstreubereiche, Testtheorie).
Nicht zuletzt bietet das Thema Zufallszahlen die Möglichkeit,
auch auf sozusagen "philosophische" Aspekte der Mathematik einzugehen:
Was ist Zufall ? Kann man wirklich Zufall mit deterministischen
Formeln beschreiben ? Dies sind Fragen, die zumindest im Unterbewußtsein
des Schülers (und nicht nur bei diesen) bestehen bleiben!
1. Ein verblüffendes Experiment - der RUN-Test
Probieren Sie es selbst einmal: Denken Sie sich eine "möglichst
zufällige" Folge von 50 Zufallszahlen aus, die den Münzwurf
simulieren soll (Wappen 0, Zahl 1). Anschließend führen
Sie das Experiment tatsächlich durch. Sie erhalten also 2 Serien von
je 50 0/1-Folgen, die beispielsweise so aussehen könnten:
1101010100101100111010111001001000101011010011101
0011100010111111010010000101011100000101011001110
Nach kurzer Zeit kann man (mit einer Erfolgswahrscheinlichkeit, die
erfahrungsgemäß bei 70-80% liegt) "erraten", welche
der beiden Folgen die gedachte und welche die tatsächliche Zufallszahlenfolge
ist.
Dieses "Experiment" führe ich seit Jahren im Unterricht
durch, um zu demonstrieren, daß selbst sogenannte "Zufallszahlen"
gewissen Gesetzmäßigkeiten gehorchen, nämlich den Gesetzen
der Statistik. Es ist dies meist das erste Mal, daß
die Schüler mit der Statistik in engeren Kontakt geraten, und dies
auf empirische Weise. Gleichzeitig wird gezeigt, daß das menschliche
Gehirn - aus welchen Gründen auch immer - einen Zufallsprozeß
nur höchst unvollkommen nachahmen kann.
Die Auswertung ist zunächst nicht streng mathematisch, für
die Schüler dafür aber leichter nachvoll-ziehbar und - was mir
wesentlich erscheint - verblüffend:
Natürlich gibt es Schüler, die einen "hereinlegen"
wollen und daher möglichst gleich viele "0"-er und "1"-er
in der gedachten Folge produzieren. In Wirklichkeit werden jedoch die Anzahl
der in der Folge vorkommenden "Blöcke" (engl. Runs)
gleicher Ziffern gezählt. Im obigen Beispiel kommen wir zu folgenden
Ergebnis:
1.Folge : 33 Runs
2.Folge : 25 Runs
Auf Grund dieses Ergebnisses würde ich keine Sekunde zögern
und behaupten, die erste Folge ist die gedanklich produzierte Folge, während
die zweite die "echte" Zufallszahlenfolge repräsentiert.
Das obige Beispiel ist nun typisch für das "übliche"
Schülerverhalten: Wenn man sich besonders anstrengt, den Zufall nachzubilden,
produziert man meist mehr "Wechsel" zwischen 0 und 1 als es den
Regeln der Statistik entspricht. Man kann dies zum Beispiel der Klasse
demonstrieren, indem der Mittelwert der Runs der gedachten und tatsächlichen
Zufallszahlenfolgen errechnet wird. Ohne entsprechende Vorkenntnisse der
Schüler wird jener der gedachten Folgen meist um einiges größer
sein als jener der "tatsächlichen" Folgen. (Alles andere
wäre typisches "Lehrerpech" gemäß dem berühmten
"Vorführeffekt").
Bei der "Auswertung" gehe ich folgendermaßen vor:
Zunächst werden die Anzahl der "Runs" der beiden Zahlenfolgen
ermittelt. Jene, deren Mittelwert näher bei 25,5 liegt, wird (natürlich
mit einer gewissen "Irrtumswahrscheinlichkeit") von mir als "wirkliche"
Zufallszahlenfolge apostrophiert. Liegen die beiden Anzahlen gleich weit
von 25,5 entfernt (etwa 24 und 27), so "passe" ich.
Die Begründung für diese Vorgangsweise liefert das Programm
von der Diskette (Programmteil RUNTEST) : Die Simulation
(Menüpunkte Mehrfachsimulation und/oder Gesetz
der großen Zahlen) zeigt, daß die Anzahl der Runs bei
einer 0-1-Zufallsfolge mit n=50 gegen 25,5 strebt. Ein Ergebnis, das näher
dem Erwartungswert 25,5 liegt, ist also "wahrscheinlicher"
als ein anderes.
(® Abb.2 bis Abb.5
im ANHANG)
Verteilung der Anzahl der Runs und Berechnung des Erwartungswert
E(Rn)
Die Anzahl der Runs bei n Versuchen mit Zufallszahlen aus dem Bereich
{0,1} folgt einer Binomialverteilung. Dies könnte auf einer höheren
Stufe (3.Jahrgang) wie folgt nachgewiesen werden.(nach [5])
:
Es werden n Ziffern X1,X2,...,Xn erzeugt, wobei gilt:
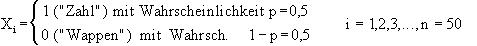
Es sei Rn die Anzahl der Runs in der Ziffernfolge X1,X2,...,Xn. Selbstverständlich
gilt:
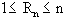
Da ein Run immer stattfindet (selbst wenn die Folge "11111111..."
oder "00000000..." lautet) betrachten wir die Anzahl der Runs
(Blöcke), die der ersten Ziffer folgen, also Rn-1.
Wir markieren jeweils den Beginn eines Runs. Die Anzahl der Möglichkeiten
für k Runs innerhalb der Folge der n-1 Zufallszahlen Xi ( i = 2..n)
ist dann 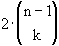 .
.
Die Multiplikation mit 2 ist notwendig, weil
die Zufallszahlenfolge entweder mit X1=0 oder mit X1=1 gestartet wurde.
Es sind in diesem Sinne beispielsweise folgende Folgen gleichwertig:
11011100001011000....
00100011110100111....
Wir berechnen nun die Wahrscheinlichkeit, daß genau k Runs innerhalb
der n-1 Zufallszahlen stattfinden: Dies erfolgt zunächst nach der
Regel  ,
anschließend wird der Term auf die gängige Formel der Binomialverteilung
umgeformt:
,
anschließend wird der Term auf die gängige Formel der Binomialverteilung
umgeformt:
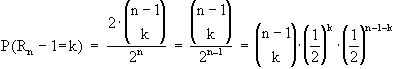
Das Ergebnis zeigt, daß Rn-1 binomialverteilt ist mit den Parametern
n-1 und p=0.5, also:
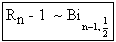
Daher können nun Erwartungswert und Varianz nach den Formeln der
Binomialverteilung berechnet werden [es gilt: E = n×
p bzw. V = n× p×
(1-p)] :
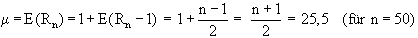
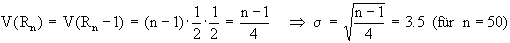
Hinweis:
Mit Hilfe der obigen Binomialverteilung kann man nun auch die Wahrscheinlichkeit
für bestimmte Anzahl von Runs berechnen. Im folgenden Beispiel wird
die Wahrscheinlichkeit berechnet, daß die Anzahl der Runs für
n=50 größer 32 (also 33 oder größer) ist.
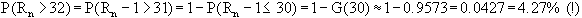
Erfahrungen mit dem RUN-Test:
Der Run-Test wurde in der eingangs beschriebenen Form bereits oftmals
von mir durchgeführt. Dabei waren einige interessante, immer wiederkehrende
Phänomene zu beobachten:
· Bereits beim Werfen der Münzen,
nachdem sie zuvor die gedachte Zufallsfolge ermittelt haben, erkennen
manche Schüler, daß oftmals viel längere Runs als vorausgesehen
auftreten (zB. 8-mal hintereinander "1"). Typischer Schülerausruf:
"Das gibt´s doch nicht!" Nur selten haben nämlich
die Schüler in ihren Zufallsfolgen Runs mit 5 oder mehr aufeinanderfolgenden
Ziffern "vorausgesehen".
Aus diesem Grund werden im Programmteil "RUNTEST" die Runs
mit Länge ³ 5 und die Länge des
in der Simulation beobachteten längsten Runs extra ausgegeben.
· Um keine falsche Erwartungshaltung
der Schüler zu provozieren, gebe ich bereits vor dem Experiment
das voraussichtliche Ergebnis bekannt (das für die Schüler unwahrscheinlich
genug klingt) : Ich behaupte, in etwa 70-80 % der Fälle die "gedachte"
Ziffernfolge erraten zu können, schließe aber nicht aus, daß
es auch einige Fälle geben kann, bei denen ich keine Entscheidung
treffen kann.
Dieses Ergebnis ist erfahrungsgemäß auch tatsächlich
zu erwarten, wobei es natürlich günstig ist, wenn die Schülerzahl
nicht zu klein ist!
· Aus Zeitgründen entscheide
ich nur bei den ersten paar Schülern "im Geheimen", anschließend
wird das Prinzip (Zählen der Runs, Mittelwert,...) erklärt und
jeder Schüler kann nun seine Folgen selber auswerten. Wie schon oben
erwähnt ist es nun sinnvoll, den Mittelwert der Runs der jeweils gedachten
bzw. geworfenen Folgen innerhalb der Klasse zu ermitteln und zu vergleichen.
Erst anschließend würde ich die Simulation am
Computer vornehmen !
2. Algorithmen zur Erzeugung von Pseudozufallszahlen
In der Anfangszeit der Computertechnik versuchte man mit rein physikalischen
Prozessen (zB. radio-aktiver Zerfall), "echte" Zufallszahlen
zu erzeugen. Doch schon bald setzten sich Verfahren durch, nach denen der
Computer - ausgehend von einer Startzahl - rein rechnerisch Zahlen erzeugt,
die dem Zufall "im Prinzip" (d.h. gemäß den statistischen
Gesetzen) entsprechen sollten. Da diese Zahlen natürlich nicht wirklich
zufällig sind (wenn man die 1.Zahl kennt, kann man alle folgenden
voraussagen), werden diese so erzeugten Zahlen Pseudozufallszahlen
genannt.
Quadratmittenmethode
Diese Methode wird heute nicht mehr verwendet, ist aber aus historischen
und didaktischen Gründen interessant. Sie stammt von J.v.NEUMANN aus
dem Jahr 1946:
Man startet mit einer beliebigen n-stelligen Zahl, bildet das Quadrat,
wählt als nächstes Folgenglied die durch die mittleren n Ziffern
gebildete Zahl usw.
Beispiel :
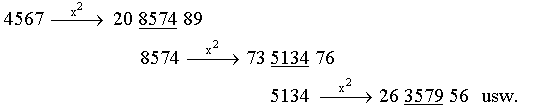
Daß unter Umständen nur sehr kurze "Zufallszahlenfolgen"
erzeugt werden (in der Fachsprache: die Periode ist zu kurz), zeigt
das folgende Beispiel - das ist auch der Grund, weshalb diese Technik heute
nicht mehr verwendet wird:
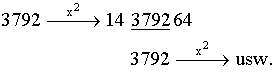
Lineare Kongruenzmethode
Diese Methode wird man in der Literatur am häufigsten antreffen,
die Idee stammt von D.H. LEHMER, 1948. Man wähle die Parameter a,c
und den Modul p (groß!) und gehe nach folgender Vorschrift
vor :
x1 ... Startwert (vorgeben oder zb. aus momentaner Zeit errechnen)
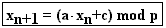
Über 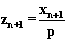 erhält
man sodann Pseudozufallszahlen, die in [0,1] gleichverteilt sein
sollten.
erhält
man sodann Pseudozufallszahlen, die in [0,1] gleichverteilt sein
sollten.
Die Frage ist nun, welche Werte von a,c,und p "gute" Zufallszahlen
ergeben. Wählt man ohne Überlegung irgendwelche Zahlen, so erhält
man fast immer einen ungeeigneten Zufallszahlengenerator. In der (mir vorliegenden)
Literatur findet man dazu unterschiedliche Angaben; dazu einige Beispiele:
"In der Praxis sollte p möglichst groß, a zwischen 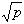 und p und c ungerade gewählt werden." ([1])
und p und c ungerade gewählt werden." ([1])
Für sehr große Simulationen sollen sich (gemäß
[2]) folgende Zahlen bewährt haben:
a = 513 ; c = 29.741.096.258.473 ; p = 248
In [6] werden einige Regeln nach D.E.Knuth wiedergegeben:
· p soll "zweckmäßig"
als Zweier- oder Zehnerpotenz gewählt werden.
· Für a wird eine Zahl vorgeschlagen,
die eine Ziffer weniger als p hat und die auf ...x21 enden sollte, wobei
x gerade sein soll.
· Schließlich wird c=1 vorgeschlagen.
In anderen Publikationen wird z.T. auf die Bedeutung von
Primzahlen zur Erzeugung von guten Zufallszahlen hingewiesen.
Auch bei der Linearen Kongruenzmethode können so wie bei der Quadratmittenmethode
bei un-günstiger Wahl der Paramter a,c und p "sinnlose"
Zahlenfolgen entstehen. Zum Beispiel führt die Wahl von a=19,c=1 und
p=381 mit der Startzahl 0 zur Folge 0,1,20,0,1,20,..., was ebenfalls eine
nicht sehr zufällige Folge darstellt.
Im Programmteil POKERTEST besteht die Möglichkeit, neben dem eingebauten
Zufallszahlen-generator einen selbstdefinierten zu wählen. Dieser
arbeitet nach der Linearen Kongruenzmethode mit folgenden Werten:
a = 897 ; c = 2111 ; p = 123456 (Die Zahlen sind [2]
entnommen)
Interessant ist, daß dieser Zufallszahlengenerator "auf den
ersten Blick" ganz brauchbare Zufallszahlen liefert, der im nächsten
Abschnitt besprochene Pokertest zeigt aber schließlich, daß
diese Folge nur "schlecht" den Zufall simuliert.
Es gibt keine ganz zuverlässige Methode zur Herstellung von Zufallsziffern.
Daher müssen die Ziffern nach der Herstellung geprüft
werden. Es genügt nicht, daß die Häufigkeiten der einzelnen
Ziffern stimmen. Es müssen auch die Häufigkeiten aller Ziffernblöcke
stimmen. Eine scharfe - und in der Praxis auch angewendete - Prüfung
ist der Poker-Test.
3. Ein scharfer Test für Zufallszahlen - der
POKERTEST
Die Idee dieses Tests ist der Vergleich der Häufigkeiten der verschiedenen
Arten von 5er-Blöcken von Pseudozufallszahlen mit den theoretischen
Wahrscheinlichkeiten. Die dabei betrachteten Möglichkeiten von 5er-Blöcken
entsprechen im Prinzip möglichen Ausgängen beim Pokern. Die folgende
Tabelle bietet eine entsprechende Übersicht :
|
Form des Blockes
|
Bezeichnung |
Beispiel
|
theoretische Wahrscheinlichkeit |
|
abcde
|
alle verschieden
(all different) |
58241
|
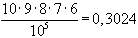
|
|
aabcd
|
ein Paar gleicher Ziffern
(one pair) |
53903
|
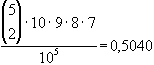
|
|
aabbc
|
zwei Paare gleicher Ziffern
(two pairs) |
67726
|
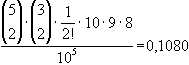
|
|
aaabc
|
drei gleiche Ziffern
(drilling) |
90499
|
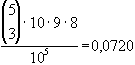
|
|
aaabb
|
drei + zwei gleiche Ziffern
(full house) |
11166
|
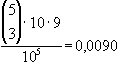
|
|
aaaab
|
vier gleiche Ziffern
(poker) |
37333
|
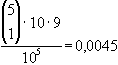
|
|
aaaaa
|
fünf gleiche Ziffern
(grande) |
55555
|
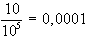
|
Die oben angeführten Wahrscheinlichkeiten lassen sich nach der
Laplace-Regel zur Bestimmung von Wahrscheinlichkeiten ( )
und der Kombinatorik errechnen.
)
und der Kombinatorik errechnen.
Der Programmteil "Pokertest" ermöglicht eine tabellarische
und graphische Übersicht, indem die durch Simulation ermittelten Werte
mit den theoretischen Wahrscheinlichkeiten vergleichen werden. Daraus ergeben
sich auf anschauliche Weise folgende Feststellungen:
· Je größer die Versuchsanzahl
n ist, desto näher werden die relativen Häufigkeiten den tatsächlichen
Wahrscheinlichkeiten kommen. ("Gesetz der großen Zahlen")
· Bei kleineren Versuchsanzahlen (zB.
n=100) sind die relativen Häufigkeiten sehr starken Schwankungen unterworfen.
Bei größer werdendem n werden diese Schwankungsbreiten immer
kleiner - d.h. man hat auf anschauliche Weise das Prinzip von Zufallsstreubereichen
erhalten.
(® Abb.9 - 12
im ANHANG)
· Der selbstdefinierte Zufallszahlengenerator
ist - das hängt mit obigem Punkt zusammen - erst bei größeren
Werten von n (sicherlich zb. für n=1000) auch optisch als "schlecht"
erkennbar.
(® Abb. 13 im ANHANG)
Auf einer höheren Stufe (möglich im 3. bzw. 4.Jahrgang) kann
man mit Hilfe von statistischen Tests auch rechnerisch überprüfen,
ob ein bestimmter Zufallszahlengenerator brauchbare Ergebnisse liefert
oder nicht. Dazu bietet sich der Chiquadrat-Test an, der auf sehr
anschauliche Weise das Prinzip eines statistischen Tests aufzeigt:
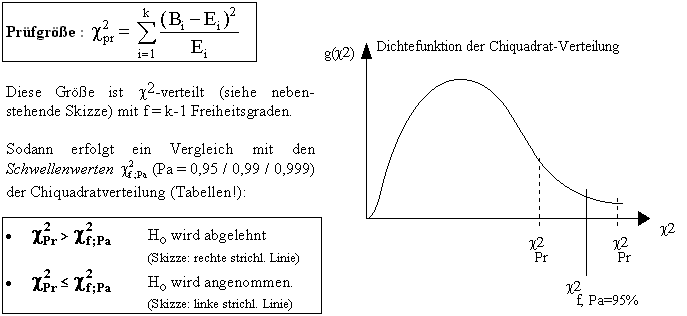
Der Chiquadrat-Test
Dieser Test überprüft, ob die Summe der (relativen)
Abweichungen zwischen den beobachteten Werten (Bi) und den erwarteten
Werten (Ei - diese ergeben sich aus den theoretischen Wahrscheinlichkeiten
gemäß obiger Tabelle) im Rahmen des Zufalls liegt oder ungewöhnlich
groß ist. Gemäß Testtheorie wird das folgendermaßen
formuliert:
Nullhypthese H0 : Die Abweichungen sind nur zufällig.
Die Irrtumswahrscheinlichkeit (d.i. die irrtümliche Ablehnung
der Nullhypothese H0 = Fehler 1.Art) beträgt a
= 1-Pa. (je nach gewähltem Niveau also 5%, 1% oder 0,1%)
Voraussetzungen:
Der Chiquadrat-Test ist nur unter bestimmten Voraussetzungen durchführbar.
Allgemein gilt:
· Keiner der erwarteten Werte Ei darf
kleiner als 1 sein.
· Höchstens 20% der Ei dürfen
kleiner als 5 sein.
Daher müssen beim Pokertest Klassen mit zu kleinen erwarteten Werten
Ei zusammengefaßt werden und die Anzahl der Simulationen (N) darf
nicht zu klein sein. Im Programmteil POKERTEST, Menüpunkt Chiquadrattest,
wurde dies folgendermaßen gelöst:
· N darf nicht kleiner als 100 sein.
· Für N < 1000 werden die
drei Gruppen mit den kleinsten Wahrscheinlichkeiten (full house, poker,
grande) zu einer Gruppe zusammengefaßt. Die Klassenanzahl k ist
somit 5 und der Freiheitsgrad f = k - 1 = 4.
· Für N ³
1000 werden nur zwei Gruppen (poker, grande) zusammengefaßt.
Es ist in diesem Fall also k = 6 und der Freiheitsgrad f = k - 1 = 5.
Hinweise zum Programmablauf
Beim Menüpunkt POKERTEST/CHI-QUADRAT-TEST kann durch wiederholtes
Drücken der Taste "V" (Versuch) der Test ständig
mit neuen Zahlen wiederholt werden.
· Durch wiederholte Simulation kann
der Begriff der Aussagewahrscheinlichkeit Pa bzw. der Irrtumswahrscheinlichkeit
a =1-Pa veranschaulicht werden : Es wird
der Wert  in 5% der Fälle
auch dann durch die Prüfgröße überschritten, wenn
die Pseudo-Zufallszahlen in Ordnung sind (wie dies bei Verwendung des internen
Zufallgenerators der Fall ist).
in 5% der Fälle
auch dann durch die Prüfgröße überschritten, wenn
die Pseudo-Zufallszahlen in Ordnung sind (wie dies bei Verwendung des internen
Zufallgenerators der Fall ist).
Mit anderen Worten: Jedes 20.Mal (im Schnitt gesehen) kommt es
zu einer Warnung, jedes 100.Mal zu einer Ablehnung von H0 mit
a =1%. Dies kann (natürlich im Rahmen der
statistischen Schwankungen) recht gut beobachtet werden.
· Der Freiheitsgrad liefert einen
Anhaltspunkt, welcher c 2-Wert unter H0 zu erwarten
ist und wird daher mit ausgegeben.
· Verwendet man den "selbstdefinierten"
(schlechten,2.) Zufallsgenerator, kann man durch wiederholtes Durchführen
des Testes feststellen, wie die Schärfe des Tests mit größer
werdendem N deutlich zunimmt. (® Text zu
Abb.13 , ANHANG-9)
· In Abhängigkeit vom Ergebnis
werden unterschiedliche Folgerungen ausgegeben:
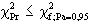 |
H0 wird angenommen - d.h. "es gibt keinen ersichtlichen Grund,
an der Qualität des Zufallgenerators zu zweifeln" |
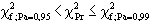 |
Warnung: "es besteht ein Verdacht, daß die Zufallszahlen
schlecht sind" |
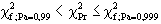 |
H0 wird abgelehnt, d.h. die Zufallszahlen gelten als "unbrauchbar"
mit Irrtumswahrscheinlichkeit a £
1%. |
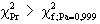 |
H0 wird abgelehnt, d.h. die Zufallszahlen gelten als "unbrauchbar"
mit Irrtumswahrscheinlichkeit a £
0,1%. |
Erfahrungen mit dem Pokertest:
Ich habe den Pokertest erstmals bei einem Vortrag von L.Rade in Klagenfurt
(1980) kennengelernt (siehe [4]) und seither im Mathematik-
und/oder EDV-Unterricht mehrere "Generationen" von PC´s
(bzw. Programmiersprachen) mit ihren eingebauten Zufallsgeneratoren danach
getestet, wie "gut" die erzeugten Zufallsfolgen sind. Einige
davon lieferten ganz "katastrophale" Ergebnisse, d.h. die erzeugten
Zufallszahlen waren sehr schlecht. Dies galt beispielsweise für den
("seligen") TI 99/4A (einen der ersten Homecomputer), aber auch
für die ältere Version des SHARP Pocket-Computer (PC-1401). Generell
ist zu beobachten, daß die Zufallsgeneratoren "immer besser"
werden, leider geht aber aus den Handbüchern in keinem mir bekannten
Fall die Formel für den Pseudo-Zufallszahlengenerator hervor (bestenfalls
ein Hinweis, daß die Zufallszahlen nach der "Linearen Kongruenzmethode"
erzeugt werden).
Da die heute gebräuchlichen Geräte bzw. Programmiersprachen
offenbar weitgehend "gute" Zufallszahlengeneratoren implementiert
haben, wurde zum Vergleich im Programmteil POKERTEST die Möglichkeit
eingebaut, einen vergleichsweise "schlechten" Zufallszahlengenerator
auszuwählen. Führt man mit diesem den Pokertest mit unterschiedlichem
N (zB. N=100, 500, 1000) durch, erkennt man auch sehr gut, daß der
Pokertest mit zunehmendem N deutlich schärfer wird (dies ist
im übrigen ein allgemeines Ergebnis der Testtheorie).
5. Literatur
[1] A.Engel: Wahrscheinlichkeitsrechnung und
Statistik, Band 1, Ernst Klett Verlag,1973.
[2] Duden "Informatik": Bibliographisches
Institut & F.A.Brockhaus AG, 1989.
[3] H.Müller (Hrsg.): Lexikon der Stochastik,
Akademie-Verlag Berlin,1980.
[4] W.Dörfler und R.Fischer (Hrsg.) : Stochastik
im Schulunterricht (Beiträge zum 3. interna-tionalen Symposium für
Didaktik der Mathematik) , Schriftenreihe "Didaktik der Mathematik"
der Universität für Bildungswissenschaften in Klagenfurt, Band
3, Hölder-Pichler-Tempsky, 1981.
[5] F.Österreicher: Vorlesungsunterlagen
"Stochastische Modellbildung", Universität Salzburg, 1993.
[6] R.SEDGEWICK: Algorithmen in C++, Addison-Wesley,
1992.
ANHANG
Hinweise zum Programmablauf
Zum Herunterladen werden 2 Versionen angeboten:
RO-STATC.EXE
: Variante mit Verwendung von Farben als unterstützendes, optisches
Hilfsmittel.
RO-STATM.EXE:
Variante, die auf die Benützung der BMUK-Laptops und Overheaddisplays
im Klassenraum zugeschnitten ist und daher weitgehend auf Farben verzichtet.
Auf der ersten Menüebene besteht die Wahl zwischen den beiden (unabhängigen)
Programmteilen
·
Runtest
·
Pokertest
Die folgenden Untermenüs bieten als ersten Menüpunkt jeweils
eine kurze Erklärung des betreffenden Programmteiles an.
Das Programm ist durchgehend so aufgebaut, daß auf der jeweiligen
Menüebene die einzelnen Menüpunkte über Cursortasten oder
mittels Anfangsbuchstaben aufgerufen werden können. Nach der Abarbeitung
eines Menüpunktes (Simulation) bestehen stets zwei Möglichkeiten,
die links unten eingeblendet werden :
Versuch - Buchstabe "V" drücken
... erneute Durchführung einer Simulation
Menü - Buchstabe "M" drücken ... Rückkehr
zum jeweiligen Menü; (als einzige Ausnahme heißt dieser Ausstieg
beim Programmteil RUNTEST/EINZELNE VERSUCHE anders: Ende/Grafik
, da nach dem Ausstieg zunächst zu einer Grafik gewechselt wird)
Abbildungen aus dem Programmablauf (Kopiervorlagen) auf den folgenden
Seiten
Es folgen auf den nächsten Seiten einige ausgewählte Bildschirmkopien
aus dem Programmablauf. Diese sollen zeigen, welche Möglichkeiten
das Programm bietet und auf der anderen Seite zum eigenen Experimentieren
anregen.

Abb.1 : RUNTEST / EINZELNE VERSUCHE
: Typischer Bildschirmausschnitt, der zeigt, daß (gar nicht so selten)
sehr lange RUNS vorkommen
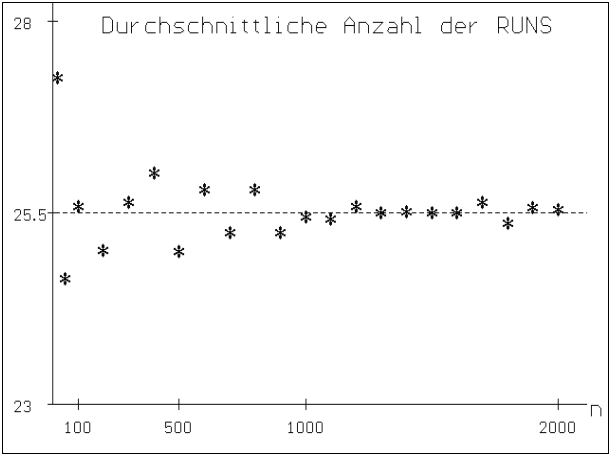
Abb. 2 : RUNTEST / GESETZ DER GROSSEN
ZAHLEN : Es wird gezeigt, daß für große n die mittlere
Anzahl der RUNS von je 50 {0,1}-Zufallsfolgen gegen 25,5 strebt.
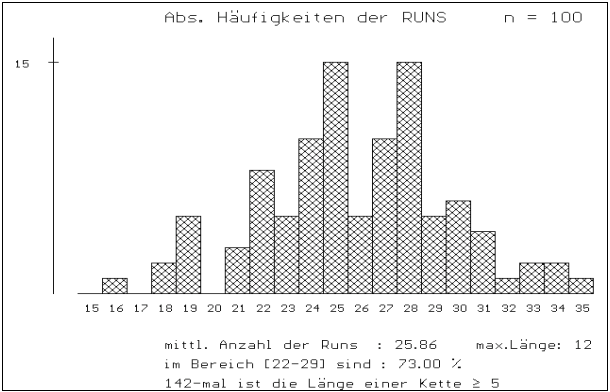
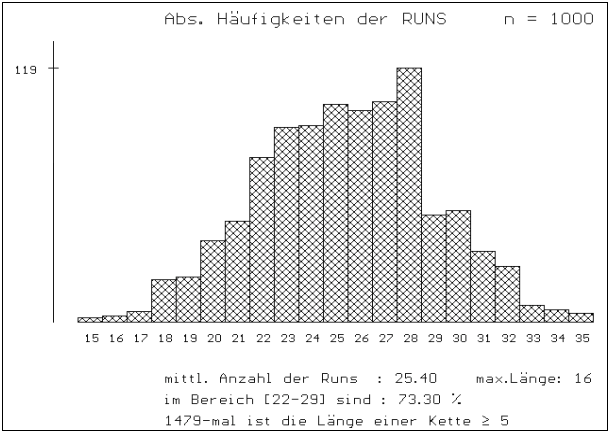
Abb.3 u. 4: RUNTEST / AUSWERTUNG VON
MEHREREN VERSUCHEN: Je niedriger n ist, desto "ausgefranster"
ist die empirische Verteilung der Runs von je 50 {0,1}-Zufallszahlen .
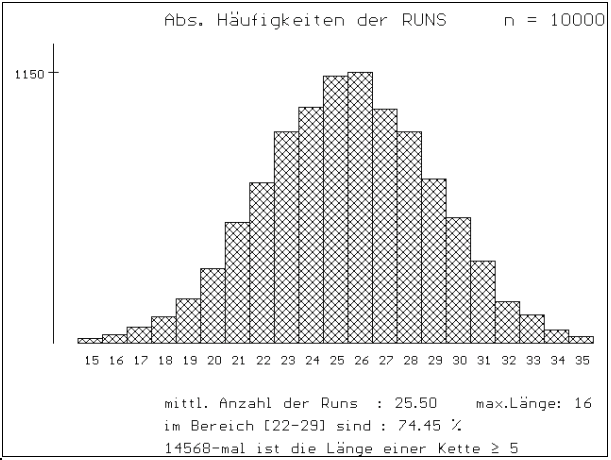
Abb..5 : RUNTEST / AUSWERTUNG VON
MEHREREN VERSUCHEN: Für n=10000 erhält man für die Anzahl
der Runs eine empirische Verteilung ähnlich der Normalverteilung;
die die tatsächliche Verteilung bereits sehr gut annähert - diese
ist eine Binomialverteilung, wie im Abschnitt 1 (Seite 3 dieses Artikels)
hergeleitet wurde.
Ferner fällt (wie schon in Abbildung 3 bzw. 4) auf,
daß manchmal - und zwar häufiger, als man gemeinhin annimmt
- sehr lange RUNS auftreten. Deswegen werden jeweils die Maximallängen
mit ausgegeben.
Der Bereich [22-29] entspricht [m
± s ] und
wird mit ausgegeben, um das Denken in Bereichen (Zufallsstreubereiche,...)
entsprechend einzuführen. Mit Hilfe der Binomialverteilung (siehe
Seite 3 dieses Artikels) kann die Wahrscheinlichkeit, daß die Anzahl
der Runs im Bereich [22-29] liegt, auch berechnet werden; man erhält:
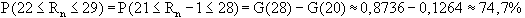
G(x) ist dabei die Verteilungsfunktion der Binomialverteilung
mit den Parametern (n-1)=49 und p=0.5.
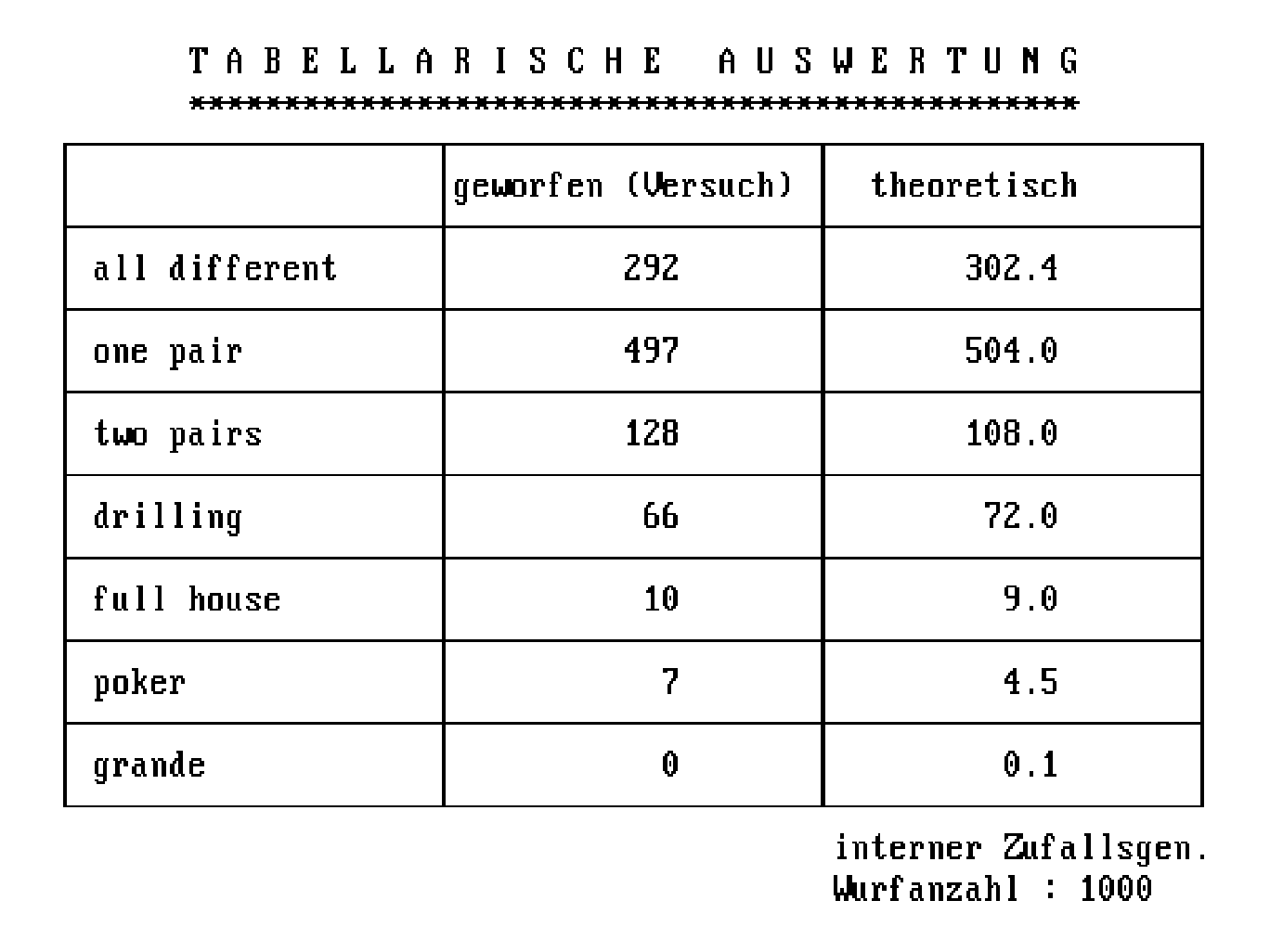
Abb. 6 : POKERTEST / TABELLE
Durchführung einer Simulation mit N=1000 Würfen
von je 5 "zehnseitigen Würfeln" unter Ver-wendung des eingebauten
(internen) Zufallgenerators.
Die "theoretischen" bzw. zu erwartendenen Werte
errechnen sich aus den jeweiligen Wahrschein-lichkeiten (siehe Tabelle
auf Seite 6 dieses Beitrags) mal der Versuchszahl N.
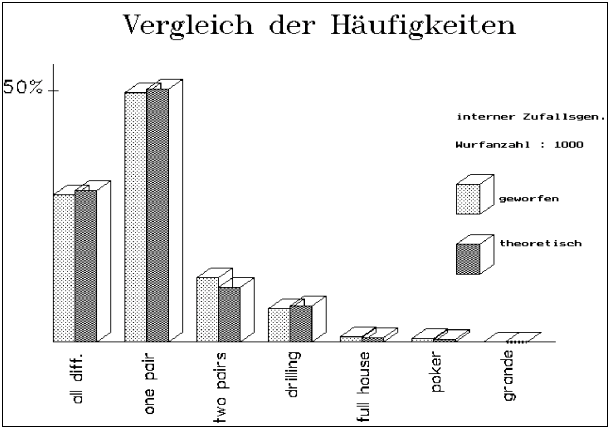

Abb. 7 : POKERTEST/DIAGRAMM bzw. CHI-QUADRAT-TEST
Die Werte aus obiger Tabelle wurden im Häufigkeitsdiagramm
dargestellt. Es stellt sich die Frage, ob die beobachteten Abweichungen
zwischen den Werten der Simulation und den zu erwartenden (theoretisch
berechneten) Werten nur "zufällig" sind.
Diese Frage beantwortet rechnerisch der Chi-Quadrat-Test:
Da die Prüfgröße kleiner als der "Tabellenwert"
(auf allen drei Niveaus) ist, gibt es "keinen ersichtlichen Grund",
an der Zufälligkeit der beobachteten Abweichungen zu zweifeln.
Übliche Sprechweisen: H0 ("die Abwechungen sind
zufällig") wird angenommen.
H0 kann nicht abgelehnt werden.
Die beobachteten Abweichungen sind nicht signifikant.
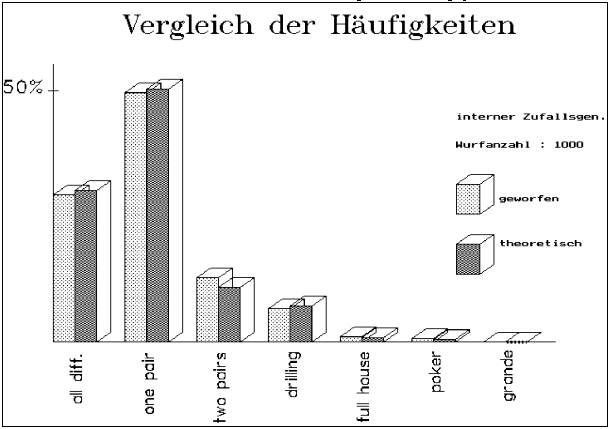

Abb. 8 : POKERTEST / DIAGRAMM bzw.
CHIQUADRAT-TEST
Gegenüberstellung eines Ergebnisses mit N=1000 unter
Verwendung des "selbstdefinierten" (schlechten) Zufallgenerators.
Ergebnis des Chiquadrattestes : H0 ("die Abwechungen sind zufällig")
wird abgelehnt, die Abweichungen sind als signifikant zu
bezeichnen.
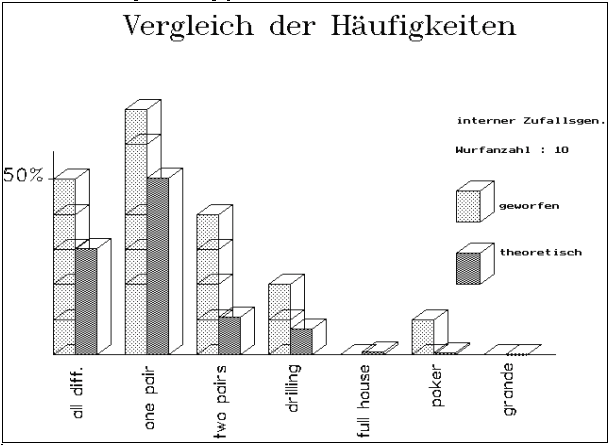
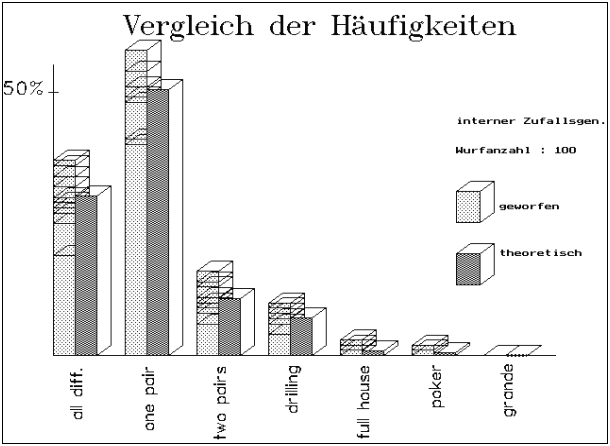
Abb. 9/10: POKERTEST / DIAGRAMM :
Starke Schwankungen bei mehreren Versuchen mit kleinem N
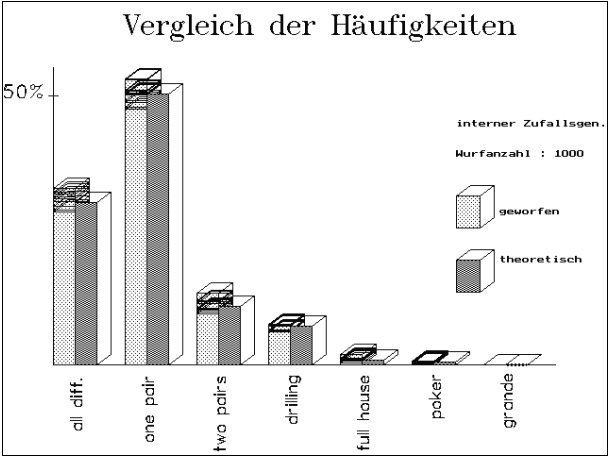
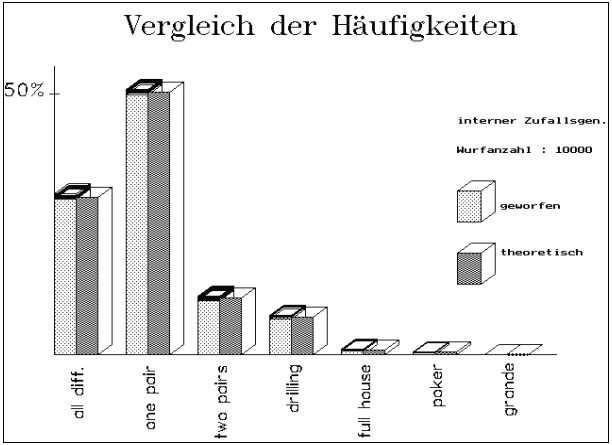
Abb.11/12: POKERTEST/DIAGRAMM : Die
Schwankungsbreite ist bei größerem N wesentlich geringer.
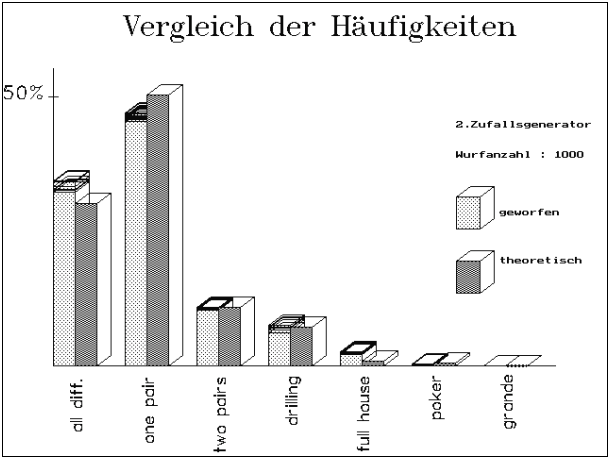
Abb.13 : POKERTEST / DIAGRAMM
Bei Verwendung des "selbstdefinierten" (oder
2.,schlechten) Zufallgenerators fällt bei größerem N auf,
daß die theoretischen Werte nicht mehr im "Zufallsstreubereich"
der Ergebnisse der Simulation liegen. Das erklärt auch die z.T. extrem
deutliche Ablehnung von H0 bei Durchführung des Chiquadrat-Tests.
Man probiere unterschiedlich große Werte von
N ( Diagramm und Chiquadrat-Test):
· N=100 : Der Zufallsgenerator
wird meist noch als "OK" klassifiziert
· N=500 : Der Test
verhält sich "indifferent": Annahmen von H0 wechseln etwa
zu gleichen Teilen mit "Ablehnung" bzw. "Warnung".
· N=1000: Der Test
ist nun so scharf, daß es praktisch nie zur Annahme von H0 kommt.