| Schätzungen für statistische Verteilungen mit dem TI83 |
Mathematische Inhalte:
1. Erheben der StichprobeTI83
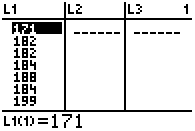
Die zu beurteilende Zufallsvariable ist die "Körpergröße in cm". Dies geschieht an Hand einer Stichprobe von 24 Jugendlichen.
Die Stichprobe wird an Ort und Stelle in der Klasse erhoben und gleich in den Taschenrechner eingegeben (Tasten/Menüfolge: [STAT] EDIT 1:Edit...)
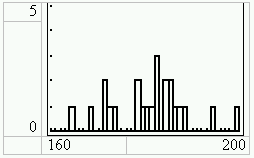
2. Darstellung als Streckendiagramm (=Histogramm mit Klassenbreite 1)
Definition des Histogramms mit [2nd][STAT PLOT] 1:Plot1:

Beachten Sie, dass (Xmax-Xmin)/Xscl£47 sein muss.
Darstellung mit [GRAPH]:
Es ist darauf zu achten, dass keine Funktionen im [Y=]-Funktionseditor zum Zeichnen markiert sind.
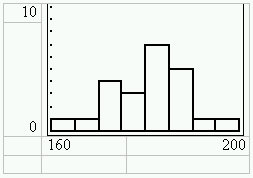
3. Darstellung der absoluten Häufigkeiten als Histogramm
Zur Verdichtung der Daten kann nun die Klassenbreite verändert werden. Die Klassenbreite für die Histogrammdarstellung wird über die WINDOW-Variable Xscl eingestellt:
[WINDOW] ... Xscl=5 ... Ymax=10.
Darstellung mit [GRAPH]:
4. Darstellung der relativen Häufigkeiten als Histogramm
Im nächsten Schritt nähern wir uns weiter dem Ziel, dass das Histogramm eine Schätzung für die Verteilung der Zufallsvariablen ist. In diesem Schritt repräsentiert die Höhe eines Balkens die relative Häufigkeit der betreffenden Klasse.
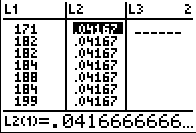
Zu diesem Zweck versehen wir jeden Stichprobenwert mit der Häufigkeit 1/24, dazu wird die Länge der Liste L2 auf 24 gesetzt und die Liste mit dem Konstanten Wert 1/24 gefüllt:
24 [STO>]dim(L2), dann Fill(1/24,L2)
Das ist zwar ein wenig langweilig, im nächsten Schritt werden wir dies automatisieren.
Zur Kontrolle im Statistik-Editor [STAT] EDIT 1:Edit... die Listen ansehen:
Die Einstellungen bei [2nd][STAT PLOT] 1:Plot1 bedürfen noch einer Änderung: Die Häufigkeitsliste Freq (vorher 1) muss noch mit der Liste L2 (=relative Häufigkeit) verknüpft werden.
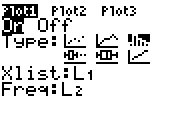
Darstellung mit [GRAPH]:
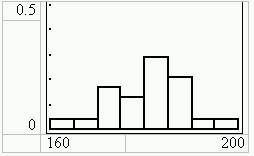
5. Das Histogramm, bei dem nun alles richtig ist
Bei einem Histogramm ist nun richtigerweise nicht die Höhe des Balkens, sondern der Flächeninhalt des Balkens ein Maß für die relative Häufigkeit, so wie das Integral der Verteilungsdichtefunktion ein Maß für die Wahrscheinlichkeit eines Ereignisses ist.
Damit nun der Flächeninhalt die relative Häufigkeit widerspiegelt, muss die
![]()
Das erreicht man durch die Verwendung einer Liste, die folgende Eigenschaften hat:
(1) Sie ist gleich lang wie die Liste L1.
(2) Sie hat den konstanten Wert (1/n)/k (n ... Stichprobenumfang, k ... Klassenbreite)
Das erreicht man unter Verwendung der Listenoperationen, die der TI83 zur Verfügung stellt.
Der Ausdruck Liste1=Liste2 erzeugt eine Liste, in der die Ergebnisse des paarweisen Vergleichs der Listeneinträge von Liste1 und Liste2 (1 für Gleichheit, 0 für Ungleichheit) eingetragen werden. Die beiden Listen müssen gleich lang sein. Die Ergebnisliste hat die gleiche Länge. Somit liefert L1=L1 die konstante Liste {1,1,1,...}die gleich lang wie L1ist.
Der Ausdruck Liste/Konstante erzeugt eine Liste in der jeder Listeneintrag von Liste durch die Konstante dividiert wird. Z.B. liefert {2,6,4}/3 die Liste {1,3,2}.
Somit liefert (L1=L1)/dim(L1)/Xscl eine Liste die (1) und (2) erfüllt (n ... dim(L1), k ... Xscl)
Wenn man nun diese Liste unter Anführungszeichen eingibt und unter einem Namen (z.B. VDF) ablegt, dann wird die Liste nicht aus den aktuellen Werten der Liste L1 errechnet, sondern es wird die Rechenvorschrift abgespeichert und bei jedem Aufruf neu aus den gerade aktuelle Werten der Liste L1 berechnet.
Eingabe im Homescreen des TI83:
"(L1=L1)/dim(L1)/Xscl"[STO>]VDF
Mit der Tastenfolge [2nd][STAT PLOT] 1:Plot1 ändert man die Häufigkeitsliste Freq auf VDF (=relative Häufigkeit/Klassenbreite). Zur Eingabe des Listennamens verwendet man 2nd[LIST] NAMES ?:VDF.

Darstellung mit [GRAPH]:
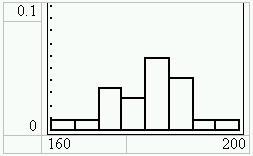
Im [Y=]-Funktionseditor eingeben: Y1=normalpdf(X,180,10)
Darstellung mit [GRAPH]:

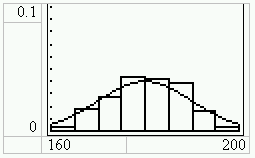
Bei einem Stichprobenumfang von 300 sieht das Histogramm aus einer simulierten Stichprobe (randNorm(180,10,300)[STO>]L1 ) so aus
7. Schätzung für die Verteilungsfunktion
Zuerst noch einmal der Unterschied zwischen Verteilungsfunktion und Verteilungsdichtefunktion:
Der Verteilungsfunktionswert gibt die Wahrscheinlichkeit dafür
an, dass die zugehörige Zufallsvariable X kleiner ist als das Argument
der Verteilungsfunktion:![]() .
Diese Wahrscheinlichkeit stellt sich bei der Verteilungsdichtefunktion
als Integral dar:
.
Diese Wahrscheinlichkeit stellt sich bei der Verteilungsdichtefunktion
als Integral dar: ![]()
In der Skizze ist jeweils die Wahrscheinlichkeit, dass sich die Zufallsvariable
X im Intervall [x1,x2[ liegt, dargestellt.
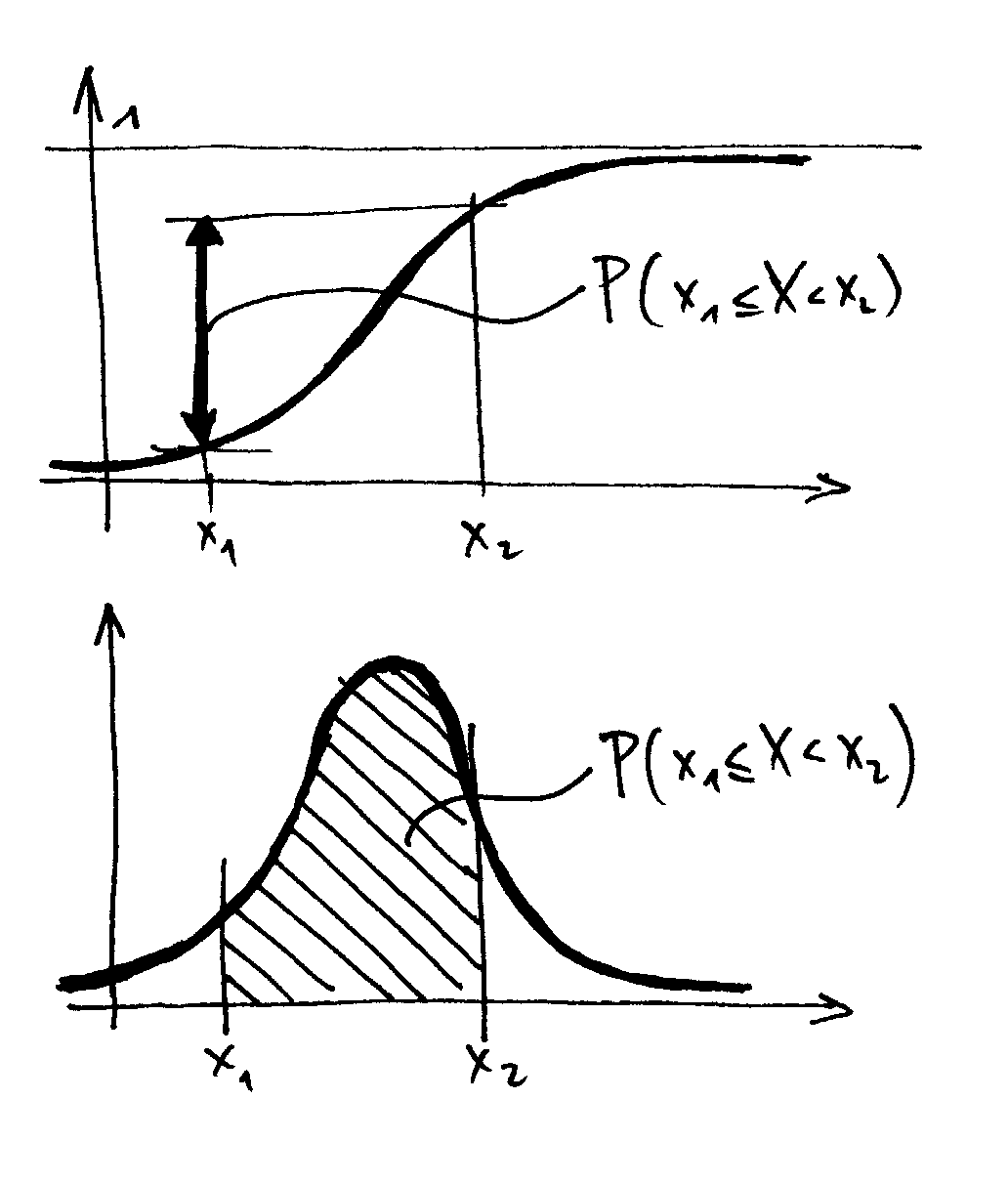
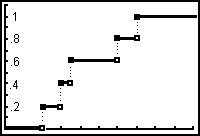
Mit dem TI83 erreicht man allerdings nur das folgende Diagramm. Bei steigendem Stichprobenumfang werden allerdings die Stufen kleiner als die Pixelgröße, sodass beide Darstellungen nicht mehr zu unterscheiden sind.
Zur Darstellung der Treppenfunktion benötigt man eine Liste, die die Werte {1, 1/n, 2/n, 3/n,... n/n=1} hat.
Dies erreicht man mit "seq(I/dim(L1),I,1,dim(L1))"[STO>] VF
Die Listendefinition wird wieder unter Anführungszeichen gestellt
und unter dem Namen VF abgelegt. Auch diese Liste wird durch die Anführungszeichen
bei jeder Verwendung neu interpretiert.
Für die Darstellung der empirischen Verteilungsfunktion definiert man mit 2nd[STAT PLOT] 1:Plot1 ein Punktdiagramm:

[WINDOW] ... Ymax=1, Yscl=0.1 ...
Darstellung mit [GRAPH]:
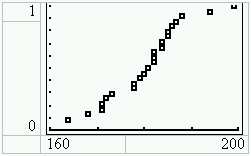
Zum Vergleich kann man eine passende Normalverteilungsfunktion über die Treppenfunktion legen und sieht gut, dass die Treppenfunktion eine Schätzung für diese Verteilungsfunktion ist. Dazu gibt man im [Y=]-Funktionseditor
Y1=normalcdf(100,X,180,10)
ein. Zu beachten ist dabei, dass an der Stelle von 100 eigentlich –? stehen müsste. 100 steht aber schon so weit links, sodass das Integral der Verteilungsdichtefunktion von –? bis 100 praktisch 0 ist. Man kann natürlich die linke Integralgrenze noch weiter nach links verschieben, es entstehen aber dadurch längere Rechenzeiten. Es ist hier ein Kompromiss zwischen Genauigkeit und Rechengeschwindigkeit geschlossen werden.
Noch einmal [GRAPH]:
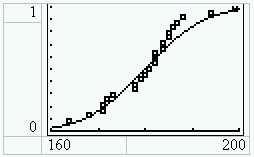
Der Vorteil dieser Schätzung ist, dass die Darstellung in keiner Weise von individuell einzustellenden Parametern (wie z.B. Klassenbreite) abhängt.
8. Schlussbemerkungen.
Ich habe in diesem Beitrag die Schätzungen für die Verteilungsdichtefunktion und für die Verteilungsfunktion immer verglichen mit einer Normalverteilung mit den Parametern µ=180 und s=10. Das kommt daher, dass ich die Stichprobenwerte für die Beispiele nicht wirklich erhoben habe (so wie ich es im Unterricht schon mache), sondern mit dem im TI83 vorhandenen Zufallszahlengenerator erzeugt habe:
randNorm(180,10,24) [STO>] L1
9. Wo die einzelnen Funktionen in der Tasten/Menü-Hierarchie des TI83 zu finden sind
| dim | 2nd[LIST] OPS 3:dim( |
| Fill | 2nd[LIST] OPS 4:Fill( |
| = | 2nd[TEST] 1:= |
| Xscl | [VARS] VARS 1:Window X/Y 3:Xscl |
| normalpdf | 2nd[DISTR] DISTR 1:normalpdf( |
| randNorm | [MATH] PRB 6:randNorm( |
| SortA | [STAT] EDIT 2:SortA( |
| seq | 2nd[LIST] OPS 5:seq( |
| normalcdf | 2nd[DISTR] DISTR 2:normalcdf( |
Siehe dazu auch das Handbuch des TI83.